
The Azure Well-Architected Framework is a set of guidelines spanning five key pillars. The first pillar of the Azure Well-Architected Framework is reliability, which is the ability of a system to remain available in the event of a failure.
Introduction
When creating solutions in Azure it’s fair to say that you have options regarding architecture and the services you look to implement. Every project will have numerous ways in which the desired outcomes can be achieved but all solutions must be underpinned by a stable foundation.
If you wanted to build your own home, you would go to an architect with a set of requirements and the architect would design your dream home for you. If you used multiple architects, you would receive multiple designs that meet your requirements, but they would all look very different. Although the designs are different, each would contain a set of fundamental pieces including walls, doors, floors and lights.
The same can be said for architecture in Azure, regardless of how you choose to meet your workload requirements, you will always have a set of fundamental areas you must think about and implement.
What is the Well-Architected Framework?
The Azure Well-Architected Framework is a set of guidelines covering the five main pillars of architectural excellence that must be covered when designing any workload.
The five main pillars covered by the framework are:
- Reliability
- Security
- Cost Optimisation
- Operational Excellence
- Performance Efficiency
Alongside the main pillars are supporting elements that are useful when creating any solution. The supporting elements include an Architectural Review, Azure Advisor, Documentation, Partners, Reference Architectures and Design Principals.
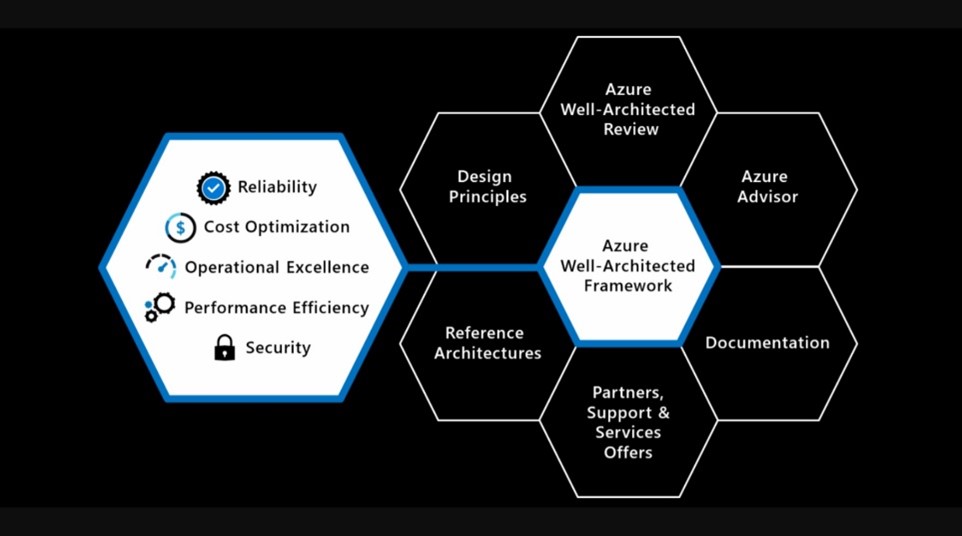
Figure 1 – Five Pillars of architectural excellence surrounded by six supporting elements.
We have created this series of blog posts to take you through the framework, the aim of this series is to ensure you have the knowledge to implement all five pillars going forward and provide confidence that going forward the design decisions you make, are correct and best practice.
Overview of Reliability
Reliability is the ability of a system to recover from failures and continue to function as intended. A reliable workload must be both resilient and available at all times. Cloud computing is a very different mindset to traditional computing and the differences carry over into the architecture and design of your solutions. When designing in the cloud you must assume your workloads will fail and with this in mind you must architect in a manner that ensures automatic recovery from the failures.
When designing for reliability in Azure there are a set of principals you must think about before deploying the workloads, those principles include:
- Define your recovery targets (SLA, RPO and RTO)
- Design your applications to be resilient with the ability recover from errors
- Plan and test for disaster recovery scenarios
- Ensure both the application and data platforms are designed for reliability
- Ensure foundational services such as networking is reliable
- Implement scalability where possible
- Monitor, measure and test your fault tolerance at all times
Reliability Services
When designing workloads, Azure provides a set of services that once implemented will assist with the principals of reliability, the main services you should be thinking about are below:
- Provide availability using Availability Sets, Availability Zones or Paired Regions
- Incorporate reliable routing and connectivity using Load Balancers, Traffic Manager, Application Gateway, Azure Front Door, ExpressRoute or Zone-redundant Gateways.
- Implement data consistency via Business Critical SKUs or Zone Redundant Azure storage.
- Scale workloads using Virtual Machine Scale Sets or Autoscaling for PaaS services.
- Ensure recoverability using Azure Site Recovery or Azure Backups
Application Reliability
As covered above the Azure platform contains multiple services that assist with reliability but when an application is designed and created it must be done in a manner that ensures it can benefit from the platform services.
When creating application, you should look to build resiliency into the system as this ensures you understand the possible faults and eliminate all single points of failure.
Dependencies are components required for an application to fully operate. Ensure you understand all application dependencies and the outcome if a specific dependency had a failure. All dependencies must separately meet your workload SLA, otherwise, they create a single point of failure which can reduce your overall SLA.
Review your workloads
We will continue to cover the remaining pillars throughout this series of blogs. Before covering more pillars, I wanted to highlight a tool Microsoft provides called the Well-Architected Review. The tool is free and can be accessed here.
The tool takes around 30 minutes to complete and covers all pillars of the framework. It’s a great resource that examines your workloads through the lenses of reliability, cost management, operational excellence, security and performance efficiency. It can even pull Advisor recommendations directly from your Azure tenant. For a more in-depth Architecture Review feel free to reach out to the Transparity Cloud Experts.

